4.2 Data categories
Data can take many successive forms, from raw collected data to very high-level aggregated data, with many steps in between. A dataset is not only the result of data collection, but also of an iterative process, comprising pre-processing, integration of different data sources, calculation of derived measures and manual and/or automatic data reduction. Aggregated data are usually the easiest to use but may only be suitable for analysing research questions similar to the initial study. In contrast, raw data can meet a larger variety of needs, but usually requires a deep technical understanding of the data collection process and sufficient data storage and operational capacity to be used in a relevant and efficient way. A trade-off, using intermediary states of the data, generally must be found, illustrated in Figure 4.
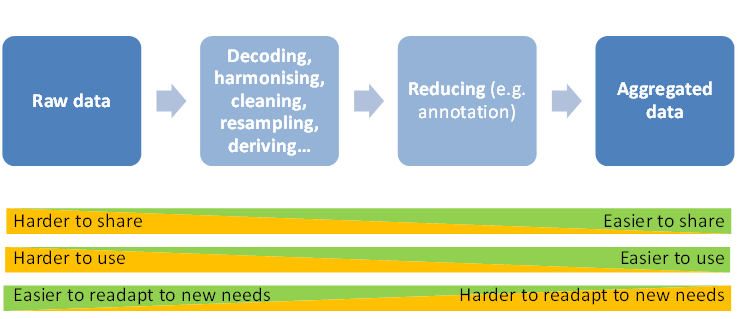
Figure 4: The trade-off between usability, usefulness, and availability
As a result, a data re-use case will typically require a combination of very different forms of data. This document proposes a way to classify them, based on two characteristics: the relations between the different entities (vehicles, users or operators in an AD setup, infrastructure, etc.) addressed during data collection, and the information which typically captures the entities’ different aspects (measures). This classification system is as close as possible, but also complementary, to the definitions in FESTA (FESTA, 2021), which essentially relate to data collection and analysis. This system emphasizes the typical structure of a CCAM dataset and contains the following main categories: context data, acquired and derived data, and aggregated data (see Figure 5). The sub-categories are described further in the following sections. Each category may contain either objective data(which is normally quantitative data), subjective data(which can be either qualitative or quantitative data), or a mix of both.
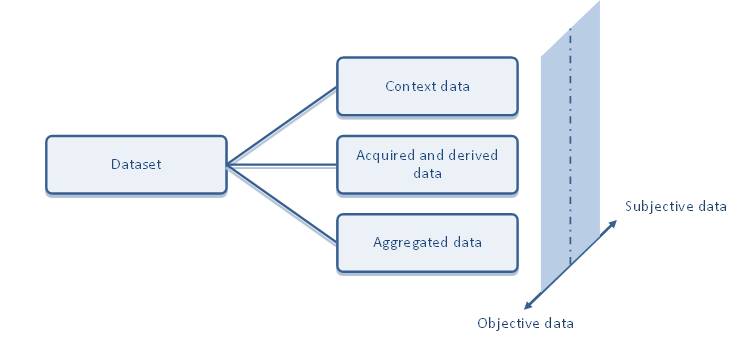
Figure 5: Dataset categories
Objective data are collected through direct physical measurement, without any influence from the experimenter or the participant’s subjective impression. They are collected using sensors, which can be pre-existing or installed on purpose, and data acquisition systems, which can be installed inside vehicles or on the roadside.
Subjective data are provided by the participants or observers, based on their impressions, feelings, memories or opinions – collected (for example) by questionnaires, travel diaries (usually quantitative data) or interviews and focus groups (qualitative data).
This categorization will be used as a basis for recommendations regarding what should be recorded in a study, and how the corresponding metadata should be created.
In each sub-chapter of 4.2.x, different sub-categories of data are described in a tree-structure. The parent category is indicated to understand the relation between the different sub-categories.